

 Android & iPhone
Android & iPhonepython爬取区块链浏览器上的交易列表数据
Bress
刚刚
前言
2022年6月3日 端午节安康。
今天主要分享如何利用爬虫爬取区块链浏览器上的交易列表数据。
原因
dune上没有bsc链上的转账明细数据表。Footprint Analytics上现有的bsc_transactions表transfer_type粒度不够。
环境
python 3.7
数据存储:mysql 5.7
缓存:redis 6.2.6
开发工具:pycharm
思路
(1)所有协议、合约、swap地址转账信息全爬不太实际,对存储要求比较高。所以针对需要分析的协议,专门去爬取对应智能合约转账是个不错的选择。
(2)区块链浏览器肯定是有反爬机制的。所以在代理选择上,要选择国外的代理。国内的代理都访问不到,具体原因你懂的。本文中不涉及代理部分,因为国外的代理厂家之前没有了解过。不过即使是上代理,对代码层面改动也比较小
(3)采用了urllib同步请求 + 范围内随机时长程序休眠。减少了被风控的概率。但是也降低了爬虫的效率。
后面再研究用scrapy或异步请求 [1]
[1] 同步:请求发送后,需要接受到返回的消息后,才进行下一次发送。异步:不需要等接收到返回的消息。
实现
找到需要爬取合约的具体地址:
第一页
http://bscscan.com/txs?a=0xbd3bd95529e0784ad973fd14928eedf3678cfad8
第二页
https://bscscan.com/txs?a=0xbd3bd95529e0784ad973fd14928eedf3678cfad8&p=2
第三页
https://bscscan.com/txs?a=0xbd3bd95529e0784ad973fd14928eedf3678cfad8&p=3
....
可以知道 p = ?就代表页数。
然后F12 点击“网络”,刷新界面,查看网络请求信息。
主要查看,网页上显示的数据,是哪个文件响应的。以什么方式响应的,请求方法是什么
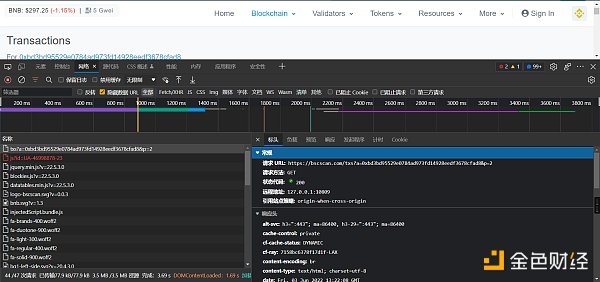
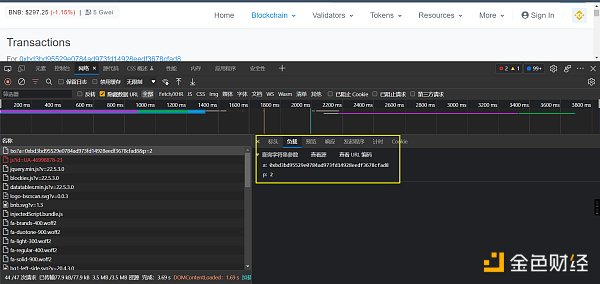
如何验证呢,就是找一个txn_hash在响应的数据里面按ctrl + f去搜索,搜索到了说明肯定是这个文件返回的。
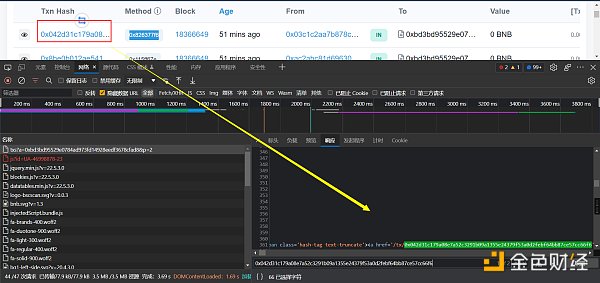
查看响应的数据,是html的格式。在python里面,处理html数据,个人常用的是xpath(当然,如果更擅长BeautifulSoup也可以)
在python里面安装相关的依赖
pip install lxml ‐i https://pypi.douban.com/simple
同时在浏览器上安装xpath插件,它能更好的帮助我们获到网页中元素的位置
XPath Helper - Chrome 网上应用店 (google.com)
然后就可以通过插件去定位了,返回的结果是list
**注:**浏览器看到的网页都是浏览器帮我们渲染好的。存在在浏览器中能定位到数据,但是代码中取不到值的情况,这时候可以通过鼠标右键-查看网页源码,然后搜索实现
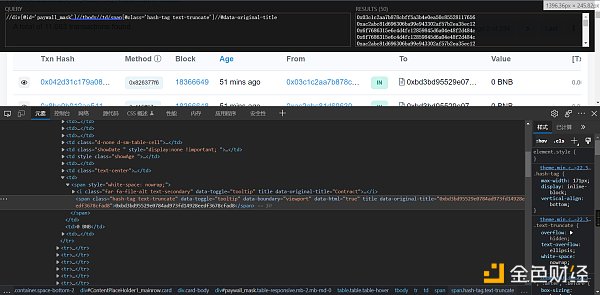
# 请求和xpath定位具体实现代码:
def start_spider(page_number):
url_base = 'http://bscscan.com
/txs?a=0xbd3bd95529e0784ad973fd14928eedf3678cfad8&'
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
'referer': 'https://bscscan.com/txs?a=0xbd3bd95529e0784ad973fd14928eedf3678cfad8'
}
# 需要传入的参数
data = {
'p': page_number
}
# 将参数转为Unicode编码格式
unicode_data = urllib.parse.urlencode(data)
# 拼接网址
# http://bscscan.com/txs?a=0xbd3bd95529e0784ad973fd14928eedf3678cfad8
url = url_base + unicode_data
# 自定义request对象
request = urllib.request.Request(url=url, headers=headers)
# 模拟浏览器发送请求
response = urllib.request.urlopen(request)
# 将返回的数据利用lxml转为
tree = etree.HTML(response.read().decode('utf‐8'))
# //div[@id='paywall_mask']//tbody//td//span/a[@class='myFnExpandBox_searchVal']/text()
txn_hash_list = tree.xpath("//div[@id='paywall_mask']//tbody//td//span/a[@class='myFnExpandBox_searchVal']/text()")
# //div[@id='paywall_mask']//tbody//td//span[@class='u-label u-label--xs u-label--info rounded text-dark text-center']/text()
method_list = tree.xpath(
"//div[@id='paywall_mask']//tbody//td//span[@class='u-label u-label--xs u-label--info rounded text-dark text-center']/text()")
# //div[@id='paywall_mask']//tbody//td[@class='d-none d-sm-table-cell']//text()
block_list = tree.xpath("//div[@id='paywall_mask']//tbody//td[@class='d-none d-sm-table-cell']//text()")
# //div[@id='paywall_mask']//tbody//td[@class='showAge ']/span/@title
age_list = tree.xpath("//div[@id='paywall_mask']//tbody//td[@class='showAge ']/span/@title")
# //div[@id='paywall_mask']//tbody//td/span[@class='hash-tag text-truncate']/@title
from_list = tree.xpath(
"//div[@id='paywall_mask']//tbody//td/span[@class='hash-tag text-truncate']/@title")
# //div[@id='paywall_mask']//tbody//td[@class='text-center']/span/text()
transfer_type_list = tree.xpath("//div[@id='paywall_mask']//tbody//td[@class='text-center']/span/text()")
# //div[@id='paywall_mask']//tbody//td/span/span[@class='hash-tag text-truncate']//text()
to_list = tree.xpath("//div[@id='paywall_mask']//tbody//td/span/span[@class='hash-tag text-truncate']//text()")
# //div[@id='paywall_mask']//tbody//td/span[@class='small text-secondary']/text()[2]
transfer_free_list = tree.xpath(
"//div[@id='paywall_mask']//tbody//td/span[@class='small text-secondary']/text()[2]")然后就是利用redis,对txn_hash去重,去重的原因是防止一条数据被爬到了多次
def add_txn_hash_to_redis(txn_hash):
red = redis.Redis(host='根据你自己的配置', port=6379, db=0)
res = red.sadd('txn_hash:txn_set', get_md5(txn_hash))
# 如果返回0,这说明插入不成功,表示有重复
if res == 0:
return False
else:
return True
# 将mmsi进行哈希,用哈希去重更快
def get_md5(txn_hash):
md5 = hashlib.md5()
md5.update(txn_hash.encode('utf-8'))
return md5.hexdigest()最后一个需要考虑的问题:交易是在增量了,也就是说,当前第二页的数据,很可能过会就到第三页去了。对此我的策略是不管页数的变动。一直往下爬。全量爬完了,再从第一页爬新增加的交易。直到遇到第一次全量爬取的txn_hash
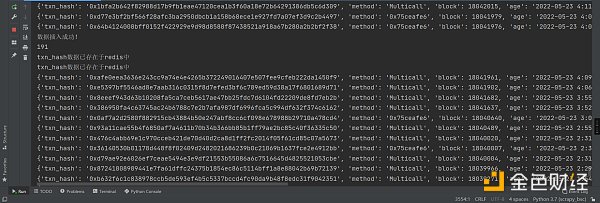
最后就是存入到数据库了。这个没啥好说的。
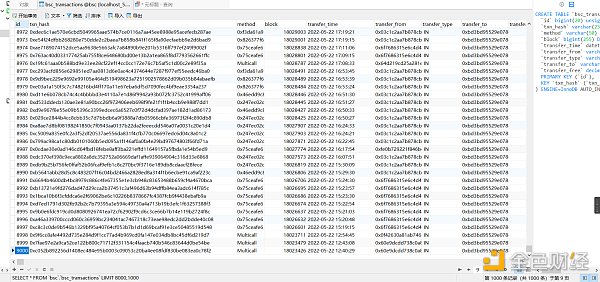
以上就可以拿到转账列表中的txn_hash,后面还要写一个爬虫深入列表里面,通过txn_hash去爬取详情页面的信息。这个就下个文章再说,代码还没写完。
今天就写到这里。拜拜ヾ(•ω•`)o
来源:Bress
作者:撒酒狂歌
 16
16
声明:本文由入驻金色财经的作者撰写,观点仅代表作者本人,绝不代表金色财经赞同其观点或证实其描述。
提示:投资有风险,入市须谨慎。本资讯不作为投资理财建议。

24小时热文




 比特币核心开发者:符文“利用了设计缺陷”
比特币核心开发者:符文“利用了设计缺陷”金色精选

 六个值得关注的空投项目盘点
六个值得关注的空投项目盘点金色财经


 CKB:比特币可编程性的新篇章
CKB:比特币可编程性的新篇章金色精选


- 寻求报道
- 金色财经APPiOS & Android
- 加入社群
Telegram - 意见反馈
- 返回顶部
- 返回底部